Mono 혹은 Flux를 다룰때 map 혹은 subscribe 동작들을 subscribeOn()이나 publishOn()을 통해 다른 스레드에서 실행될 수 있도록 위임할수 있는데 인자는 Scheduler를 받습니다.
Spring WebFlux에서 Controller 스레드에서는 blocking 작업을 할수 없도록 되어있기에 필요한 경우에 subscribeOn() 를 사용하여 blocking 작업을 다른 스레드에서 사용할 수 있는데 Scheduler 종류마다 blocking 작업이 가능한 Scheduler가 있고 아닌 Scheduler 가 있습니다. (non-blocking 스케줄은 블럭킹 작업이 불가능합니다.)
새로 신규로 생성하여 넘길수 있겠지만 Schedulers가 기본적으로 몇가지를 지원합니다.
parrallel
optimized for fast non-blocking executions
속도 최적, non-blocking
single
optimized for low-latency one-off executions
스레드 하나를 공유함, non-blocking
elastic
optimized for longer executions, alternative for blocking tasks where the number of active tasks can grow indefinitely
긴작업에 최적, non-blocking 아님, blocking 작업 가능 스레드, 필요시 무한히 늘어남
boundedElastic
optimized for longer executions, alternative for blocking tasks where the number of active tasks is capped
긴작업에 최적, non-blocking 아님, blocking 작업 가능 스레드, 정해진 사이즈
Zookeeper는 Zookeeper 단독으로도 사용되지만, 하둡이나 카프카 등 여러 다른 시스템들과 함께 활용되고 있지만
저의 경우에는 Zookeeper 자체에서 어떤 기능들을 제공하는지 조차 모르고 사용하기도 했습니다.
그래서 조금씩 파악중이며 조금씩 수정해갈 예정입니다.
Zookeeper는 기본적으로
메타 저장소
데이터 변화 감시를 위한 Watcher
데이터 snyc 혹은 분산 어플리케이션을 위한 lock 제공
간단한 설정을 통한 클러스터 지원 와 같은 기능들을 제공하며(이것 말고도 많겠지만)
참고로 메타는 각 노드에 저장되며, 노드는 트리구조로 되어있고, 트리를 쉽게 접근할수 있도록 파일시스템과 같이 접근할 수 있습니다(/data/node1/info).
그리고 노드도 여러가지 종류들을 제공합니다.
Ephemeral Nodes
세션동안 유지되는 노드, 연결이 끊어지면 삭제
Sequence Nodes
고유명을 위한 노드
Container Nodes
락을 위한 노드(3.5.3에 추가됬다고 하는데 사용을 아직 못해봤네요)
TTL Nodes
마찬가지로 3.5.3에 추가
분산 어플리케이션들은 보통 Zookeeper의 클라이언트가 되고, Connection을 지속적으로 유지하고 있습니다.
Zookeeper에서 데이터 변화 감지를 위해 Watcher를 제공하기 때문에 polling을 하며 감시 할 필요 없이 동작만 CallBack 코드만 작성해 두면 되기에 훨씬 간결해 질 수 있습니다.
Watcher의 경우 노드 하나 변화에 Wacher를 설정할 수 있고, 노드 하위에 변화에도 대해 설정 할 수 도 있습니다.
데이터 변화에 대한 Watcher
get -w /data
데이터 하위 생성에 대한 Watcher
ls -w /data
Zookeeper를 활용하여 할수 있는 것들은 많겠지만 일단 간단하게 구현 해본 부분은 "분산 어플리케이션에서 서로의 노드 추가 삭제 감지 에 따른 동작" 상위 Node를 하나 생성하고, 어플리케이션마다 하위에 ephemeral + sequence Node를 생성하고 서로 상위 Node를 Watcher 하게 하면 간단히 분산 어플리케이션에서 어플리케이션 변화를 감지 할 수 있고 Watcher 코드에 대응되는 동작을 넣는것으로 간단히 "분산 어플리케이션 상황에서 각 어플리케이션 감지 및 동작" 을 처리 할 수 있습니다.
해당 글은 Zookeeper를 살펴보거나 사용할 때 마다 기록을 위해 업데이트 할 예정입니다.
한 달 동안 잠시 해외를 다녀온 사이 Spring Boot 2.2가 릴리즈 되었습니다. 지금까지 버전업 되면서 변경 사항들을 모두 파악하지는 못했지만 계속 사용하게될 SpringBoot이기 때문에 2.1x에서 2.2x로 올라가며 변경돼 사항을 파악하고자 릴리즈 노트를 번역 및 개인적으로 궁금한 사항을 파악해보았습니다.
Spring 5.2가 Java 13을 지원함에 따라 Spring Boot2.2도 Java 13을 지원하며, Java11과 Java8 또한 지원합니다.
@ConfigurationProperties 생성자 바인딩 지원
설정 properties는 이제 생성자 바인딩을 지원하기 때문에 클래스의 불변을 지원합니다. @ConfigurationProperties를 붙이거나, @ConstructorBinding를 붙이면 생성자 바인딩이 활성화되며, @DefaultValue와 @DateTimeFormat 이 생성자 바인딩으로 동작합니다.
RSocket 지원
RSocket에 대한 자동 설정을 지원합니다. spring-boot-starter-rsocket
("var ${var}" 도 그렇고.. data class도 그렇고 null check도 그렇고 너무 많네요..;;)
몰랐던 기능이 있어 기록을 남깁니다.
먼저 "default argument"
자바에서 보통 인자가 없을때 그리고 인자가 있을때 처리를 위해
메소드 오버로딩으로 처리하곤 합니다
이코드가 결국에는 default 값 처리를 위한 건데
결국 arg가 없는 메소드를 열어봐야 기본값을 알 수 있습니다.
public void hello(){
hello("kim");
}
public void hello(String name){
System.out.println("Hello " + name);
}
/////////아니면 아래처럼 null로 넘기고 null이면 기본값 처리하는 방법이..
public void hello(){
hello(null);
}
public void hello(String name){
String localName = name;
if(localName==null){
localName="kim";
}
System.out.println("Hello " + localName);
}
그런데 코틀린에서는 아래와 같이 코드를 작성해서 default argument를 설정할 수 있습니다.
fun hello(name: String="kim")=println("hello ${name}")
훨씬 간결해집니다.
그럼 인자가 많아지거나 다양해지면 어떻게 하나?
(몇개는 입력을 받고 몇개는 default로 처리하고 싶을때... )
자바로 작성하면 null체크를 덕지덕지 처리를 해주기도하고
overload 메소드를 거의 종류별로 만들어야 하는 경우도 생기기 때문에
args가 늘어나는것 대신 보통 input용 클래스를 빌더패턴으로 만들던 그냥 data 클래스로 만들던 만들어서 코드를 처리하기도 합니다.
public void order() {
order(null, -1);
}
public void order(int cnt) {
order(null, cnt);
}
public void order(String menuName) {
order(menuName, -1);
}
public void order(String menuName, int cnt) {
String localName = menuName;
if (localName == null) {
localName = "대표메뉴";//default Menu
}
int localCnt = cnt;
if (localCnt == -1) {
localCnt = 1;// default Cnt
}
System.out.println(menuName + " order " + cnt);
}
코틀린에서는 "named argument"를 써서 쉽게 처리할 수 있습니다.
fun order(menuName: String="대표메뉴", cnt: Int=1)=println("${menuName} order ${cnt}")
여기까지는 위에 default argument와 동일합니다.
여기서 중요한건 사용할때 기존 order(null,10) 형태로 호출하는것이 아니라
아래와 같이 인자를 줄때 변수을 명시해서 넘길수 있습니다.
order("피자", 5)//결과적으로 "피자 order 5", 모두 채운 기존 형태
order(3)//에러
order("피자")//결과적으로 "피자 order 1"
order(menuName = "피자")//결과적으로 "피자 order 1"
order(cnt = 3)//결과적으로 "대표메뉴 order 3"
order(menuName = "피자", cnt = 5)//결과적으로 "피자 order 5"
order(cnt = 5, menuName = "피자")//결과적으로 "피자 order 5", 순서 상관없이 잘 동작합니다
named argument 덕분에 첫번째 인자가 어떤 변수인지 두번째 인자가 어떤 arg인지
메소드 선언을 보지 않아도 호출하는 쪽에서 변수명을 명시하면 혼동을 덜할수 있고
arg순서가 바뀌거나(물론 유지보수를 위해 메소드 arg를 막 변경하는 사람은 없겠지만) arg가 늘어나는 경우에도
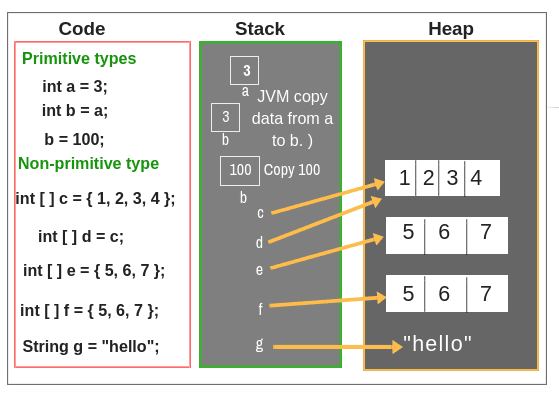
primitive type을 두어 primitive는 heap에 할당하지 않고 스택에 value를 바로 value를 저장하여 성능 향상한 것으로 알고 있습니다.
primitive를 통해 성능 향상한 것은 좋지만, java Collection을 통해 int를 담거나 제네릭으로 타입을 처리하거나
할 때 primitive로는 처리가 불가능하기 때문에
primitive를 wrapping 타입(Integer)으로 변경해야 하는 경우가 필요하곤 합니다.
물론, java에서 자동으로 primitive에서 wrapping 타입 변환(auto-boxing) wrapping에서 primitive(auto-un-boxing)을 해주기도 하지만, 편리할 뿐 boxing 때마다 object가 생기고 사라지기 때문에 그리 성능상 좋지는 않고 불편하기도 합니다.
(NPE 문제.. 타입 처리 문제...)
불편하기도 하지만 성능 때문이라도 계속 primitive 타입이 존재하죠..
그래서, 많은 연산 시에는 wrapping 타입 대신 primitive 타입을 사용하라곤 합니다.
int[] values = {...};
int sum=0;
for(val : values){
sum+=val;
}
Integer sum=0;//이렇게 하지 말라곤 하죠
for(val : values){
sum+=val;//이렇게 하지 말라곤 하죠
}
그런데!
코틀린은 이 불편한 primitive가 없다고 합니다.
(실제로 코틀린은 int 대신 Int, double 대신 Double)
없어져서 좋을 수 있지만, "그럼 코틀린은 wrapping 타입만 사용한다는 걸까? 그럼 느리지 않을까?"
라는 의문이 생겼습니다.
그럼 위에서 언급한 연산 때마다 객체가 생기고 사라지고를 반복해서 문제가 생기지 않을까요?
그래서 테스트해봤습니다.
테스트 방법은
1. 테스트 코드 작성
2. class 파일 생성
3. 디컴파일러로 class 파일 확인
을 통해 어떻게 class 파일이 생성되는지 확인하려고 합니다.
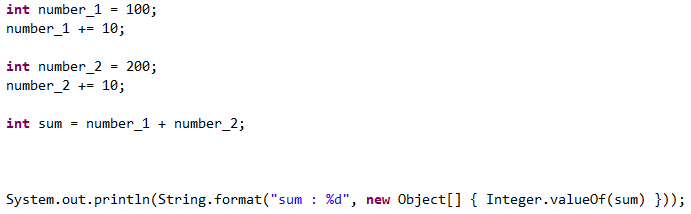
1. 자바
먼저, 자바로 primitive일 때
int number_1 = 100;
number_1 += 10;
int number_2 = 200;
number_2 += 10;
int sum = number_1 + number_2;
System.out.println(String.format("sum : %d", sum));
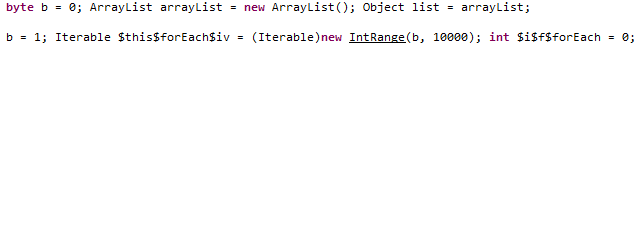
하단은 디컴파일러를 통해 본 자바 primitive 코드
거의 차이가 없습니다. 다만 마지막 라인에 String.format()에
마지막 arg는 Object []이기 때문에 Integer.valueOf()로 오토 박싱 한 부분이 보입니다.
지금까지 객체는 마지막 한 번만 객체 생성이 되겠네요
(물론 정확하게는 Integer.valueOf()가 내부적으로 범위 값만큼은 객체를 캐싱을 하고 있기 때문에 객체를 만들지 않겠지만요..)